
{kind=link}
In this blog we will go through how stable diffusion models work.This Blog is mainly Summary of the Fastai video. We will be using diffusers library by huggingface.
Lets understand the intuition of these.
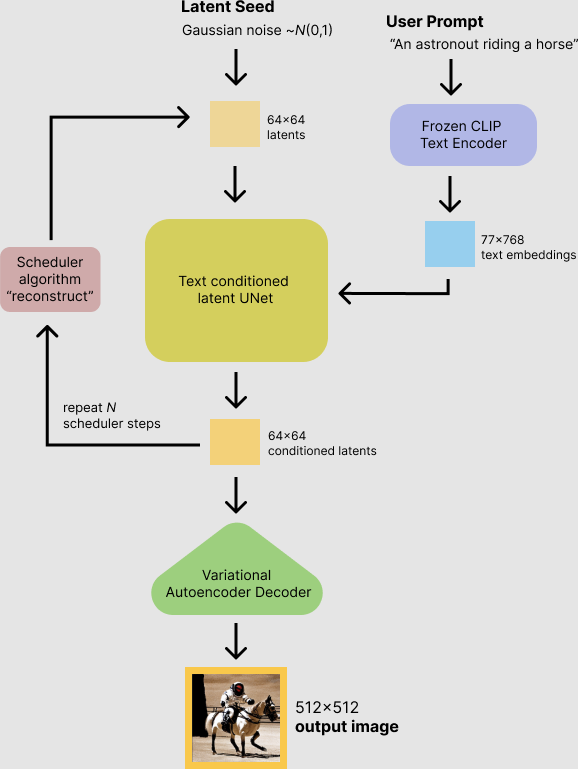
Lets say we have alot of images. We will add random gaussian noise to the images. Now we have images with somewhat noise. Lets take these images and train a model which extracts the noise we have added.
Now we have model which given noisy image extract noise and we can have image generated.

As our model knows to extract somewhat noise , so given so pure noise we can iterate for X steps to the get some tangable output.

{kind=link}
why not run it only once?

As you can see from above example.In first iteration it may extract some noise. Again it will be given to extract. This when we do for X steps we get the final output.
Now instead of random image generated, can we guide the model to generate specfic images? Yes.
In the above model, along with noisy image if we also give embedding of text as input to train. The model will understand what to generate. This method is called as Classifier-Free Guidance.
Lets see quick example using huggingface pipeline
pipe2 = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16).to("cuda")
prompt = "a photograph of an astronaut riding a horse"
pipe2(prompt).images[0]
Generally images are 3d with alot of values. A small 512*512 image will have 786432 values. But from information persepective alot of values don’t add value. So we use VAE. This model compress image into small dimension, which gives only important values which actually adds value. This will reduce our inputs which will reduce the computation.
We may need to use de compression during output to get proper image.
What are the blocks till now we saw?
- Model which extracts noise and outputs less noise image.
- Model which embeds the text into embedding.
- Model which compresses and de-compressed images. ( output of these compression models are called as latents)
In next blog we will go through components of Stable Diffusion with code. Next>>